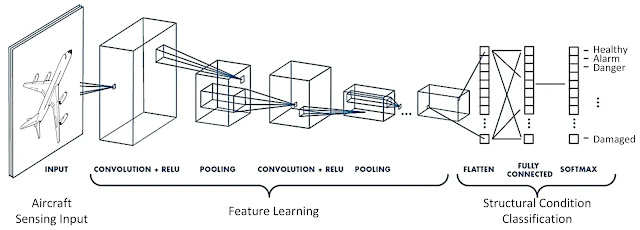
Loss & Cost Functions

Loss Functions In neural networks, after a forward propagation, the loss function is calculated. The loss function is the result of the difference between actual output and the predicted output. Different loss functions will return different values for the same prediction, and thus have a considerable effect on model performance.\ Regression Loss Functions Mean Squared Error Loss Mean Squared Logarithmic Error Loss Mean Absolute Error Loss Binary Classification Loss Functions Binary Cross-Entropy Hinge Loss Squared Hinge Loss Multi-Class Classification Loss Functions Multi-Class Cross-Entropy Loss Sparse Multiclass Cross-Entropy Loss Kullback Leibler Divergence Loss Cost Functions Cost functions for Regression problems: Mean Error (ME) Mean Squared Error (MSE) Mean Absolute Error (MAE) Root Mean Squared Error (RMSE) Categorical Cross Entropy Cost Function. Binary Cross Entropy Cost Function. Mean Absolute Error This function returns the mean of absolute differences among prediction...