ReLU Activation Function
ReLU Activation Function



Advantages:
- It is cheap to compute.
- It is easy to optimize
- converges fast
- No vanishing gradient problem
- It is capable of outputting a true zero value allowing the activation of hidden layers in neural networks to contain one or more true zero values called Representational Sparsity
Disadvantages:
- The downside for being zero for all negative values called dying ReLU. So if once a neuron gets negative it is unlikely for it to recover. This is called the “dying ReLU” problem
- If the learning rate is too high the weights may change to a value that causes the neuron to not get updated at any data point again.
- ReLU generally not used in RNN because they can have very large outputs so they might be expected to be far more likely to explode than units that have bounded values.


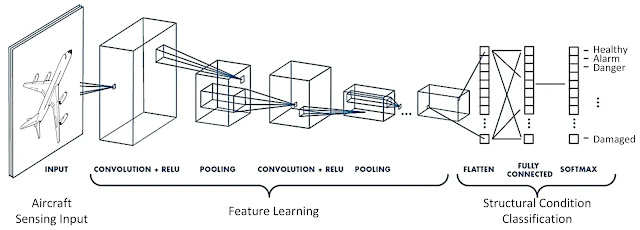
Comments
Post a Comment